







炒股就看,權威,專業,及時,全麵,助您挖掘潛力主題機會!

文 / 一燈
過年這陣子最火熱的話題,恐怕要數《哪吒2》和DeepSeek。
一個是中國古代神話傳說人物,另一個是AI領域的後起之秀。本來八竿子打不著的兩家,卻在這個春節意外地“相映成趣”。

圖源:DeepSeek官網
不少人這陣子可能一直有在關注DeepSeek的進展,也包括那83個小時的保衛戰。當他們坐在電影院,看到十二金仙對龍族的爭議,看到“捕妖隊”抓無辜妖眾去煉丹,看到龍族退無可退後的反擊,心中或許會十分感慨:果然藝術來源於生活,而生活更加殘酷且沒有道理。
所以,盡管已經有不少媒體報道過了DeepSeek,但《節點財經》在這裏還是想再講一講自己所看到的DeepSeek,以及該公司模型以外的事。
繞過三座山,打開AI
這陣子有關DeepSeek公司和旗下AI大模型的介紹已有很多,因此這裏我們不再贅述其成績,就簡單聊一聊它對行業的一些啟示。
首先,可以“繞過”算力,用算法彎道超車。
以往,大家普遍認為算力是AI的核心,發展AI就是要不斷的堆算力、堆GPU。
而就在大家燒錢堆算力的時候,DeepSeek選擇燒腦改算法。
MLA(多頭潛在注意力機製)技術大幅降低了長文本推理成本,MoE(混合專家模型)創新解決了路由崩潰難題,多令牌預測(MPT)顯著提升推理速度,這三大創新分別針對 Transformer 架構中的不同瓶頸,成為DeepSeek能夠以小博大的關鍵所在。

DeepSeek v3架構概覽圖,圖源:CSDN
這裏舉個簡單的例子,傳統的大模型就好比一家擁有眾多服務員和廚師的餐廳,每個服務員從頭到尾獨立負責自己客人的記菜單、傳菜、結賬、清潔等工作。當複雜的菜品出現時,全部廚師都圍上來討論誰能做、怎麽做。
這就可能會出現多個服務員重複記錄相同訂單、傳菜時堵在廚房門口、廚師資源浪費等重複勞動和效率低下的問題。
而在DeepSeek的模型設計中,MLA技術讓所有服務員共享一個智能平板,能實時同步訂單、桌號、菜品狀態(省去重複記錄);上菜時,隻有負責上菜的服務員工作,其他人在需要時才會介入(按需分工)。這樣既能更快地完成任務,又能保證每部分任務的完成質量。
同時,多令牌預測能讓服務員在顧客點主菜後,立馬建議甜點和飲料,提前準備服務,而不是等顧客一個個點完,從而使服務更加流暢、體驗更好。
MoE模型則清楚每個廚師都擅長的菜係,在麵對複雜的菜品時,模型能夠根據菜品的特點,智能地將其分配給最合適的廚師處理,從而提高處理效率,減少不必要的資源浪費。
這些創新技術與架構的運用,讓DeepSeek-R1的預訓練在2048塊英偉達H800 GPU(性能受限版本)集群上就能完成,費用隻有557.6萬美元。而OpenAI等企業訓練模型,則需要數千乃至上萬塊Nvidia A100、H100等頂級顯卡,動輒數億美元的訓練成本。
可見,當AI行業普遍沉迷於“算力軍備競賽”時,DeepSeek的“出圈”證明:與其瘋狂堆服務器,不如優化算法結構,針對技術瓶頸實施“靶向治療”,才能讓大模型甩掉 耗電怪獸 的帽子,開啟低成本高性能的新紀元。
其次,可以“繞過”通用,從垂直場景切入。
根據DeepSeek公布的跑分數據顯示,DeepSeek-R1在培訓後階段大規模使用強化學習技術,在數學、代碼、自然語言推理和其他任務上,其性能可與OpenAI o1正式版本媲美,而價格僅為o1的3%。
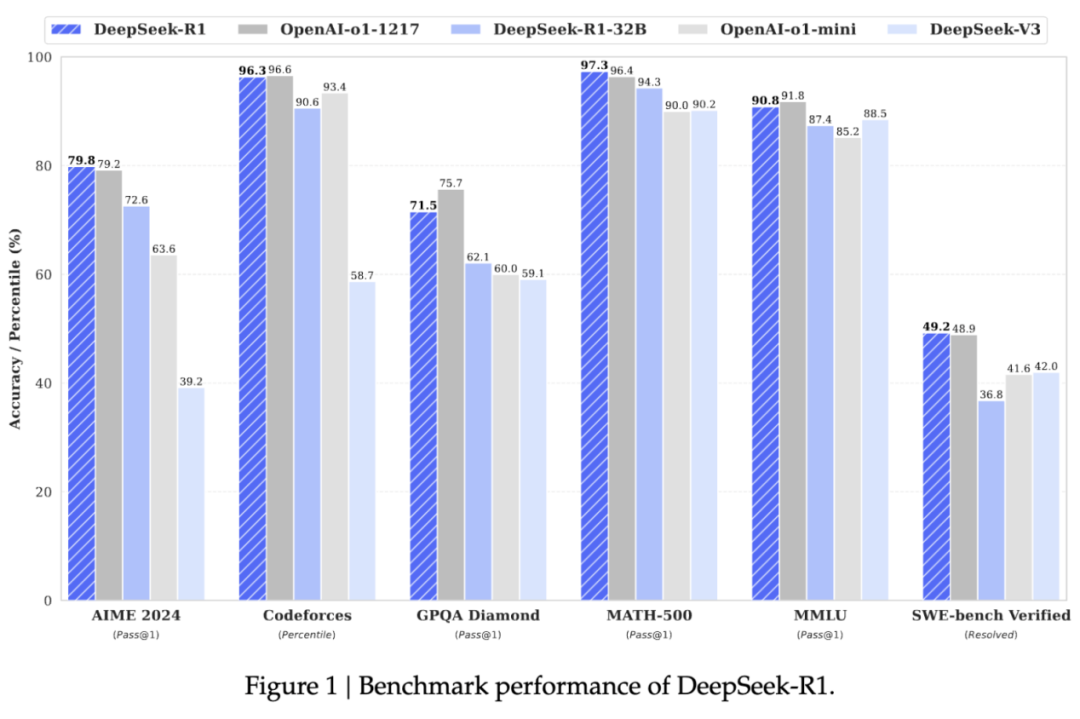
圖源:DeepSeek
但這並不意味著DeepSeek-R1超越了OpenAI o1,畢竟OpenAI優先追求的是“通用智能”,投入大量資金人力,想要的是全能通才的效果。國內企業開發AI大模型也大都沿用這一思路,希望自家大模型沒有什麽明顯的能力短板,快速達到可商用水平。
而DeepSeek選擇從垂直場景切入,先追求在部分領域(如數學、代碼)的表現更優,再逐步分階段完善其他領域的能力。這是一種能夠快速成長和建立差異化優勢的發展策略。
值得一提的是,文心一言作為紮根於中國市場的大語言模型,根據百度官方的介紹,在多項中文評測中,文心一言4.0的表現已經超越了目前最強的GPT-4模型。這意味著在理解和生成中文內容方麵,文心一言也已成為了全球最頂尖的AI模型之一。
因此,《節點財經》認為,中國AI企業尤其是創業公司,不必都紮堆死磕“全能大模型”,可選擇垂直場景靶向爆破:這樣既能規避與通用模型的算力絞殺戰,又能通過構建起數據護城河,進而在細分領域闖出一片天。
最後是,可以“繞過”商業,堅持對技術求索。
這次DeepSeek之所以能引起這麽大的轟動,除了模型本身表現優異、開發和訓練成本大幅降低,還有較為重要的一點是,DeepSeek主張免費開源。
要知道,目前比較知名的其他大模型,無論是國內百度的文心一言、華為的盤古大模型,還是海外的OpenAI、Llama等產品,都基於商業化和競爭考量,要麽一開始選擇了閉源路線,要麽逐漸走向閉源,要麽雖宣稱開源,但卻設立了不少限製,並未做到真正意義上的開源。
相比之下,DeepSeek不僅完全開放代碼,還放出了詳細的技術報告;不僅開源了自己最大的 671B R1 模型,還幫大家蒸餾量化好了 1.5B~70B 多個尺寸的模型;不僅提供所有的訓練數據、訓練腳本、論文等,還選擇了最寬鬆的 MIT License 協議,允許任何人免費使用、修改、分發,包括用於商業用途。
DeepSeek創始人梁文鋒此前談及對於開源的構想是,DeepSeek未來可以隻負責基礎模型和前沿的創新,其他公司在 DeepSeek的基礎上構建To B、To C的業務。“這一波浪潮裏,我們的出發點,就不是趁機賺一筆,而是走到技術的前沿,去推動整個生態發展。”

圖源:“湛江發布”微信公眾號
在《節點財經》看來,或許是因為背靠千億量化基金,也或許就是純粹的理想主義,至少從目前來看,DeepSeek團隊重技術突破多過商業變現,要行業繁榮不要壟斷優勢。
正如英偉達高級研究科學家Jim Fan評論的那樣:“我們生活在這樣一個時代,一家非美國公司正在讓OpenAI的初衷得以延續,即做真正開放、為所有人賦能的前沿研究。”
明槍與暗箭,暴露了誰在心虛
1月28日,多位美國官員指出,DeepSeek是“偷竊”,正對其影響開展國家安全調查。隨後,部分國家和組織也開始“重點關注”DeepSeek:
●⠦„›爾蘭數據保護委員會向DeepSeek發出信函,要求其提供有關如何處理愛爾蘭公民數據的詳細信息;
●⠦„大利數據保護機構也采取了類似措施,他們認為DeepSeek對意大利數百萬人數據造成風險,DeepSeek需要在20天時間裏作出回應;
●⠦퐦€…組織還認為,DeepSeek在保護和限製未成年人方麵的做法還不夠健全,從年齡驗證到未成年人數據處理都沒有明確的強製執行方案;
......
而據彭博社報道,近期OpenAI與微軟展開了一項聯合調查,針對DeepSeek去年使用OpenAI API接口的賬戶進行審查,並以涉嫌違反服務條款的模型蒸餾為由,取消了他們的訪問權限。
在國內輿論場,也有一些所謂的“極客”開始對DeepSeek的技術細節發起攻擊,聲稱DeepSeek涉嫌“抄襲”或“技術不透明”,並試圖通過論文和數據來證明這一點。
當然,以美國為首的西方國家在意的不止DeepSeek。
華爾街日報日前曾發布報道《It’s Not Just DeepSeek. A Guide to the Chinese AI Companies You Need to Know》,提醒美國人要注意哪些中國大模型公司,並著重指出,百度在中國最早推出麵向公眾的生成式AI文心一言,如今已經擁有4.3億用戶。⠂ ⠀

圖源:華爾街日報
如果說這些明麵上的指控是真是假還有待查證,不能認為是西方國家在刻意抹黑、打壓、搞認知戰,但在1月25日~29日期間,DeepSeek服務器集群莫名受到每秒超過2.3億次DDos惡意請求,攻擊總量相當於整個歐洲三天的網絡流量總和。
據了解,為了保護DeepSeek,360安全響應中心第一時間拉響警報,鎖定攻擊特征碼;華為雲啟動流量清洗係統,為服務器搭建防護盾不到12小時就確定了攻擊源頭全部來自美國,並予以反擊。
與此同時,網易雷火的遊戲服務器陣列緊急轉換為流量緩衝池;用AI識別0.00017%的真實用戶,菜鳥網絡貢獻物流算法優化帶寬,釘釘開通緊急通訊確保指揮暢通......阿裏雲、、泰山雲、新華三等企業也都紛紛加入DeepSeek保衛戰,貢獻自己的力量。
1月29日晚8點,經過83個小時的鏖戰,中國互聯網企業成功將攻擊流量壓製97.2%,捍衛住了DeepSeek和中國AI產業尊嚴。
然而,這場中美AI角力下的網絡安全保衛戰隻是一個開始。據XLab實驗室監測發現,1月30日淩晨,針對DeepSeek(深度求索)線上服務的攻擊烈度突然升級,其攻擊指令較1月28日暴增上百倍。
並且,至少有2個Mirai變種僵屍網絡參與攻擊,分別為HailBot和RapperBot。此次攻擊共涉及16個C2服務器的118個C2端口,分為2個波次,分別為淩晨1點和淩晨2點。
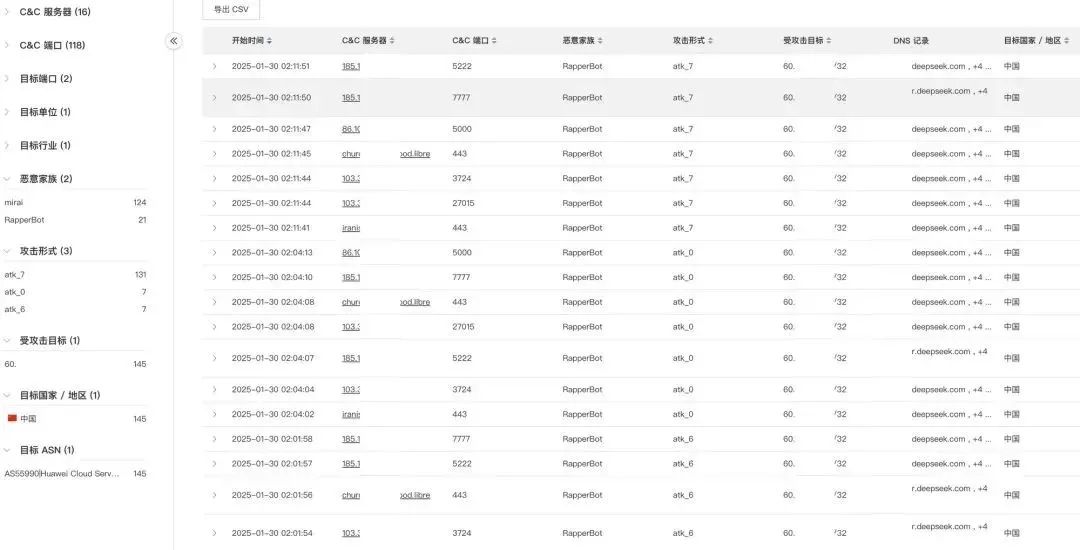
部分攻擊指令詳情⠂ 圖源:奇安信
說好的公平競爭、創新取勝,結果是明槍暗箭、防不勝防。
說實話,盡管DeepSeek在模型本身和創新路徑上確有成績,但遠沒有達到超越OpenAI、算法“封神”的地步。畢竟算力才是大模型可持續發展的必要條件,也是我們的短板,盡管DeepSeek找到了一些優化算力使用的方法,但這並不意味著算力需求變得可有可無。
因此,在《節點財經》看來,DeepSeek的出現,還算不上是技術上的革命性突破,更多的是讓大家開始重新思考如今AI領域的基礎研究角度、商業層麵的既有模式。但當下,DeepSeek卻得到了全球“熱度”,無所不用其極的圍剿,不亞於當年對付華為。
這樣的氛圍中,心虛的是誰?帶節奏的是誰?想要霸權永固的又是誰?其實不言而喻。
總結
DeepSeek就像是初露鋒芒的哪吒,也是純粹的理想主義者,正試圖以技術突破打破封鎖,用開源生態重構行業規則。
未來,DeepSeek能走多遠、能開源多久尚未可知,但這想要改變AI世界的想法,當下也足以令人興奮。
畢竟,“因為我們都太年輕,不知道天高地厚。”⠀
*題圖由AI生成
郵箱:lizi@jdcaijing.com
